
В этом году они выбрали ускорители машинного обучения как для обучения, так и для логических выводов, связь между чипами со сверхвысокой пропускной способностью и «блок обработки инфраструктуры» (IPU) для разгрузки управления центром обработки данных.
Теслу пригласили для описания D17-нанометровый обучающий процессор машинного обучения, используемый в эксамасштабном компьютере Dojo.
D1 имеет 50 млрд транзисторов размером более 645 мм.2реализуя 354 вычислительных узла и 576 линий SerDes со скоростью 112 Гбит/с для обмена данными между кристаллами в пакете «система на пластине», что обеспечивает общую скорость обработки BFP16/CFP8 362 Тфлоп/с на частоте 2 ГГц.
Что бросается в глаза в IC, так это ее отход от традиционной глобальной синхронной синхронизации.
Чтобы уменьшить скачки тока питания, связанные с глобальным тактированием, и, следовательно, уменьшить количество металлических слоев, необходимых для распределения питания, D1 использует мезохронное распределение тактового сигнала.
Он может это сделать, потому что его узлы находятся в прямоугольном массиве, а пути от узла к узлу проходят только между ближайшими соседями.
По сути, часы вводятся в верхний левый угол массива, и каждый узел рекомбинирует часы от соседей сверху и слева, а затем отправляет свои новые часы вниз и вправо. В результате фронт тактовой волны распространяется по диагонали через узлы сверху слева направо и снизу.
Большая часть остальной части документа Теслы ISSCC описывает, как эта схема была смоделирована и реализована в деталях — например, конденсаторы металл-изолятор-металл были встроены в металлический блок для дальнейшего снижения шума переключения.
Syntiant пригласили рассказать о своем нейронном процессоре принятия решений NDP200 (справа)который может выполнять сетевой тест MobileNetV1 со скоростью 5 кадров/с и средней мощностью 830 мкВт при напряжении питания ядра 900 мВ.
Разработанный для локальной (без подключения к облаку) обработки изображений, энергопотребление было ключевым параметром проектирования, что побудило архитектуру с памятью (Syntiant Core 2) свести к минимуму энергозатратное перемещение данных во время логического вывода.
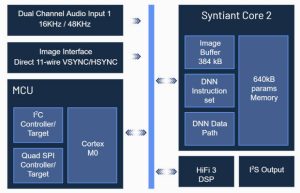
Получившаяся 40-нм ИС (левый) также имеет Tensilica HiFi3 DSP и Arm Cortex M0 для дополнительной обработки.
Nvidia описала свой 5-нм канал связи NVLink C2C между чипами который соединяет Grace-Hopper и Grace Superchip с 10 каналами, обеспечивающими скорость 900 Гбайт/с между Grace и Hopper или между двумя чипами Grace.
Он имеет архитектуру с опережением тактовой частоты с широкополосным контуром фазовой автоподстройки частоты в приемнике для регулировки перекоса для каждой дорожки и широкополосным отслеживанием джиттера между путями данных и тактовых импульсов.
Две метрики канала: 552 Гбит/с/мм.2 чипа и 40 Гбит/с/вывод – последнее при ≤10-15 частота ошибок по битам во внепакетном канале с потерями 12 дБ. Он «увеличивает скорость одностороннего соединения с привязкой к земле до 40 Гбит / с с достаточным запасом, чтобы выдерживать большие объемы производственных изменений для соединений вне упаковки», — заявила Nvidia.
Наконец, Intel рассказала о своем IPUа также конвейер обработки пакетов, RDMA, хранилище, включая разгрузку и внутреннюю обработку NVMe.
«Серверные архитектуры сегодня включают в себя диск с каждым сервером, и, поскольку емкость трудно предсказать, дисковое хранилище выделяется избыточно, что приводит к неиспользованию емкости. С IPU вы можете перейти на бездисковую серверную архитектуру», — заявили в Intel.
Устройство имеет 16 ядер Arm Neoverse N1, выделенное резервное шифрование и сжатие.
движок, три канала интерфейса DDR4 или LPDDR4 и выделенный движок управления системой.
Документ ISSCC 2023 9.1: 7-нм обучающий процессор ML с распределением тактовых импульсов
ISSCC 2023, документ 9.2 Постоянно включенный нейронный процессор для глубокого обучения компьютерного зрения мощностью 1 мВт
Документ ISSCC 2023 9.3 NVLink-C2C: когерентное межкомпонентное соединение «чип-чип» со скоростью 40 Гбит/с на контакт
несимметричная сигнализация
Документ ISSCC 2023 9.4 Подробный обзор Intel IPU E2000
Международная конференция IEEE по твердотельным схемам, ежегодно проводимая в Сан-Франциско, представляет собой (и, возможно, «лучшую») мировую выставку аналоговых, цифровых и радиочастотных схем на базе интегральных схем. Это дает возможность инженерам по проектированию интегральных схем и схем поддерживать техническую актуальность и общаться с экспертами.
Читать полную новость на сайте
/cloudfront-us-east-2.images.arcpublishing.com/reuters/X3XRYCRH7FLHNMFWNHGGEK2FII.jpg "Инфосис просит некоторых сотрудников возвращаться в офис 10 дней в месяц: источник")
/cloudfront-us-east-2.images.arcpublishing.com/reuters/2JHTHFCRGNMOPNJFHUVXYE6GNM.jpg "Тему и Шеин проигрывают Amazon в онлайн-покупках на праздники")


/cloudfront-us-east-2.images.arcpublishing.com/reuters/THGEYHQTCJLDJK76BXFB74YS5A.jpg "Блок выходит на новый уровень, сфокусировав свое внимание на прибыльности, придавая облик ралли PayPal")
