«Наш алгоритм использует классическое планирование топологического пути и глубокое обучение с подкреплением», — сообщает Университетская группа по робототехнике и восприятию.
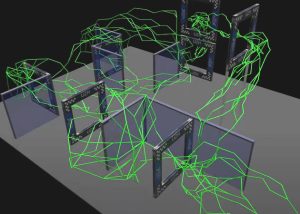
На первом этапе (Правильно) многие пути без столкновений находятся с использованием вероятностного метода стержневой карты.
После этого пути фильтруются с использованием различных стратегий обхода препятствий (внизу слева).
Именно эти пути, а также знания о физической динамике реального или смоделированного транспортного средства используются для управления алгоритмом обучения с подкреплением, целью которого является создание политики, которая максимизирует продвижение квадрокоптера по выбранному пути, избегая при этом препятствий.
Обучение с подкреплением использует метод проб и ошибок для оптимизации своих параметров и может работать с нелинейными динамическими системами.
«Вся эта информация используется нейронной сетью для вычисления желаемой коллективной тяги», — говорят исследователи. «Затем полис обучается, когда он сначала учится медленно летать по трассе и избегать столкновений. После этого ограничения по скорости и удалению от направляющего пути снимаются, и полис учится облетать путь за минимальное время».
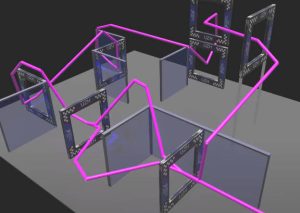
 В двух реальных экспериментах (Правильно), обученный алгоритм вел дрон по заданному курсу с тягой, ограниченной 16 Н или 28 Н. Даже на искривленной ограниченной экспериментальной трассе он развил скорость до 42 км/ч и испытал ускорение до 3,6 g.
В двух реальных экспериментах (Правильно), обученный алгоритм вел дрон по заданному курсу с тягой, ограниченной 16 Н или 28 Н. Даже на искривленной ограниченной экспериментальной трассе он развил скорость до 42 км/ч и испытал ускорение до 3,6 g.
«Мы показали, что обученная политика выполняет самые современные алгоритмы в сложных макетах дорожек и значительно более надежна, чем классические конвейеры отслеживания планирования», — говорят в команде.
Бумага 'Обучение минимальному времени полета в загроможденной среде’ описывает исследование в IEEE Robotics and Automation Letters.
Группа робототехники и восприятия указывает на препринт статьи здесьи есть видео - из которого были взяты приведенные выше изображения.
/cloudfront-us-east-2.images.arcpublishing.com/reuters/LH6QBXHH2BLABJJL4E4AY4YD7Q.jpg "ЕС рассматривает расширение системы сертификации кибербезопасности")




